STRING
Der Datentyp STRING besteht aus zwei Teilen:
Einem Header mit der maximalen und der aktuellen Bytezahl
Eine Reihe (Zeichenfolge) von bis zu 32767 Byte, je nach Speichergröße der SPS, die eine beliebige Zeichencodierung und sogar Binärdaten enthalten kann
Weitere Informationen finden Sie im Abschnitt "Interne Speicherstruktur von Zeichenfolgen auf der Steuerung".
Beispielvorgänge mit Variablen des Datentyps STRING:
Auffüllen von Zeichenfolgenvariablen mit Zeichenfolgenliteralen oder Konvertierungsfunktionen wie WORD_TO_STRING, FP_FORMAT_STRING...
Verwenden und Bearbeiten von Zeichenfolgenvariablen mit Zeichenfolgenbefehlen wie CONCAT, LEFT...
Willkürliches Zugreifen auf Zeichenfolgenvariablen mit Adress-Sonderfunktionen wie Adr_OfVarOffs… oder über spezielle überlappende SDTs wie den vordefinierten überlappenden SDT STRING32_OVERLAPPING_DUT
Austauschen von Daten mit externes Geräten über Dateien, HTML-Seiten oder Monitoringbefehle
In Control FPWIN Pro7 werden die folgenden beiden Zeichencodierungen vor allem von Zeichenfolgenliteralen und von der Monitorfunktion unterstützt:
Latin-1-Codierung, eine feste Ein-Bit-Zeichenkodierung nach ISO 8859-1 (Latin-1), die Unicode-Zeichen von 0x00–0xFF unterstützt
UTF-8-Codierung, eine Multi-Byte-Zeichencodierung mit Zeichen, die aus 1 bis 4 Byte bestehen, die alle Unicode-Zeichen von 0x00–0x10FFFF unterstützt
Die Latin-1- und UTF-8-Zeichencodierung behandeln die Zeichen im Bereich von 0x00–0x7F gleich wie ASCII-Zeichen.
Die Zeichencodierungen sollten nicht kombiniert werden. Weitere Informationen finden Sie im Abschnitt "UTF-8-Zeichencodierung verwenden".
Zeichenfolgenliterale
Zeichenfolgenliterale enthalten eine Folge von Zeichen oder Escape-Sequenzen, die von einfachen Anführungszeichen (') begrenzt sind.
Zeichenfolgenliterale können an folgenden Orten verwendet werden:
In den Deklarationseditoren zum Initialisieren einer Variablen des Datentyps STRING
In den Programmrümpfen als Eingangsargumente
Folgende Zeichenfolgenliterale sind verfügbar:
Mit Latin-1 codierte Zeichenfolgenliterale, die Unicode-Zeichen von 0x00–0xFF unterstützen
Typenlose mit Latin-1 codierte Zeichenfolgenliterale ohne Präfix, wie 'abc'. Wenn sie ASCII-fremde Zeichen im Bereich von 0x80–0xFF enthalten, z.B. 'äöü', wird eine Warnung generiert.
Bespiele für typenlose Latin-1-Zeichenfolgenliterale:
Unicode-Block
Typenloses Latin-1-Zeichenfolgenliteral
Bytes in hexadezimaler Darstellung
Anmerkung
Leere Zeichenfolge
''
''
Basic Latin (0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
Bei Verwendung wird eine Warnmeldung erzeugt.
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
Typgebundene mit Latin-1 codierte Zeichenfolgenliterale mit dem Präfix latin1# wie latin1#'abc' oder latin1#'äöü'
Bespiele für typgebundene Latin-1-Zeichenfolgenliterale:
Unicode-Block
Typgebundenes Latin-1-Zeichenfolgenliteral
Bytes in hexadezimaler Darstellung
Anmerkung
Leere Zeichenfolge
latin1#''
''
Basic Latin (0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
Bei Verwendung wird keine Warnmeldung erzeugt.
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
UTF-8-Zeichenfolgenliterale
Mit UTF-8 codierte Zeichenfolgenliterale mit dem Präfix utf8#, wie utf8#'abc', utf8#'äöü' oder utf8#'ä+漢+🙏', können alle Unicode-Zeichen von 0x00–0x10FFFF in 1 bis 4 Byte codieren.
Beispiele für UTF-8-Zeichenfolgenliterale
Bytes pro Zeichen
Unicode-Block
UTF-8-Zeichenfolgenliteral
Bytes in hexadezimaler Darstellung
Leere Zeichenfolge
utf8#''
''
1
Basic Latin
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
Latin-1 Supplement
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
Griechisch
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK Hiragana
utf8#'ゖ'
' E3 82 96'
CJK Katakana
utf8#'ヺ'
' E3 83 BA'
CJK Unified
utf8#'囆'
' E5 9B 86'
4
CJK Unified
utf8#'𫜴'
' F0 AB 9C B4'
Emoticon
utf8#'🙏'
' F0 9F 99 8F'
Escape-Sequenzen
Escape-Sequenzen können in 8-Bit-Zeichenfolgenliteralen sowie in UTF-8-Zeichenfolgenliteralen verwendet werden.
Dabei wird die Kombination der drei Zeichen, Dollar-Zeichen ($) gefolgt von zwei hexadezimalen Ziffern, als die hexadezimale Darstellung des 8-Bit-Zeichencodes interpretiert.
Zeichenfolgenliteral
Bytes in hexadezimaler Darstellung
Anmerkung
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
AnmerkungWenn Sie in eine UTF-8-Zeichenfolge eine ungültige UTF-8-Bytefolge einfügen, ist das Ergebnis eine ungültige UTF-8-Zeichenfolge.
Beispiel
Input
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
sString10 definiert als STRING[10]
Operation
sString10:= utf8#'敬敬$FE$FF敬具'Ergebnis
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
Folgen aus dem Dollarzeichen und einem weiteren Zeichen werden gemäß folgender Tabelle interpretiert:
Zeichenfolgenliteral
Bytes in hexadezimaler Darstellung
Anmerkung
'$$'
utf8#'$$'
' 24'
Dollarzeichen
'$''
utf8#'$''
' 27'
Einfache Anführungszeichen
'$L' oder '$l'
utf8#'$L' oder utf8#'$l'
' 0A'
Zeilenvorschub
'$N' oder '$n'
utf8#'$N' oder utf8#'$n'
' 0D 0A'
Neue Zeile
'$P' oder '$p'
utf8#'$P' oder utf8#'$p'
' 0C'
Formularvorschub
'$R' oder '$r'
utf8#'$R' oder utf8#'$r'
' 0D'
Wagenrücklauf
'$T' oder '$t'
utf8#'$T' oder utf8#'$t'
' 09'
Tabulator
Monitoring je nach Typ der Zeichenfolge
Wählen Sie im Monitorbetrieb die Standarddarstellung, damit die Zeichenfolgenbytes entsprechend der erkannten Zeichencodierung richtig angezeigt werden:
Typ der Zeichenfolge |
Präfix |
Standarddarstellung |
Hexadezimale Darstellung |
Programmierbeispiel ST-Editor |
|---|---|---|---|---|
Mit Latin-1 codierte Zeichenfolge |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (typgebundenes Latin-1-Zeichenfolgenliteral verwenden, um Warnmeldung zu vermeiden) |
|
UTF-8-Zeichenfolge |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
Gemischte Zeichenfolge |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
Monitoring im Anwendermonitor: Es sind zwei Darstellungen möglich: Standard und hexadezimal.
Monitoring in Programmiereditoren: Standarddarstellung im Rumpf und in der Quick-Info, hexadezimale Darstellung nur in der Quick-Info.
STRING-Deklaration
Verwenden Sie für die Deklaration von STRING-Variablen im POE-Kopf die folgende Syntax:
STRING[n], mit n = Bytezahl
Die Voreinstellung für den Initialwert, z.B. bei der Variablendeklaration im POE-Kopf bzw. in der globalen Variablenliste, ist ein leeres Feld, das durch " begrenzt wird.
Ungültige Zeichenfolgen
Kriterien für ungültige Zeichenfolgen:
Die maximale Anzahl an Bytes, die für die Zeichenfolge reserviert sind, ist negativ oder größer als 32767.
Die aktuelle Anzahl an Bytes, die in der Zeichenfolge enthalten sind, ist negativ oder größer als 32767.
Die aktuelle Anzahl an Bytes, die in der Zeichenfolge enthalten sind, ist größer als die maximale Anzahl an Bytes, die für die Zeichenfolge reserviert sind.
Interne Speicherstruktur von Zeichenfolgen auf der Steuerung
Jedes Zeichen der Zeichenfolge wird in einem Byte gespeichert. Der Speicherbereich für eine Zeichenfolge umfasst einen Kopf (2 Worte) und jeweils ein Wort für zwei Zeichen.
Das erste Wort enthält die Anzahl an Bytes, die für diese Zeichenfolge im Speicher reserviert werden.
Das zweite Wort enthält die aktuelle Bytezahl in der Zeichenfolge.
Nachfolgende Worte enthalten je zwei Bytes der Zeichenfolgenzeichen.
Geben Sie die Zeichenfolgenlänge mit folgender Formel an, um einen Bereich im Speicher für eine STRING[n] zu reservieren:
Speichergröße = 2 Worte (Kopf) + (n+1)/2 Worte (Bytes)
Der Speicher ist wortweise organisiert. Deshalb wird immer auf die nächst höhere Ganzzahl gerundet.
Wort-Offset |
Höherwertiges Byte |
Niederwertiges Byte |
|---|---|---|
0 |
Maximale Anzahl an Bytes, die für die Zeichenfolge reserviert sind |
|
1 |
Aktuelle Anzahl an Bytes, die in der Zeichenfolge enthalten sind |
|
2 |
Byte 2 |
Byte 1 |
3 |
Byte 4 |
Byte 3 |
4 |
Byte 6 |
Byte 5 |
... |
... |
... |
1+(n+1)/2 |
Byte n |
Byte n-1 |
Zeichencodierungen
Die Latin-1- und UTF-8-Zeichencodierung behandeln die Zeichen im Bereich von 0x00–0x7F gleich wie ASCII-Zeichen, wie im Unicodeblock Basis-Lateinisch definiert.
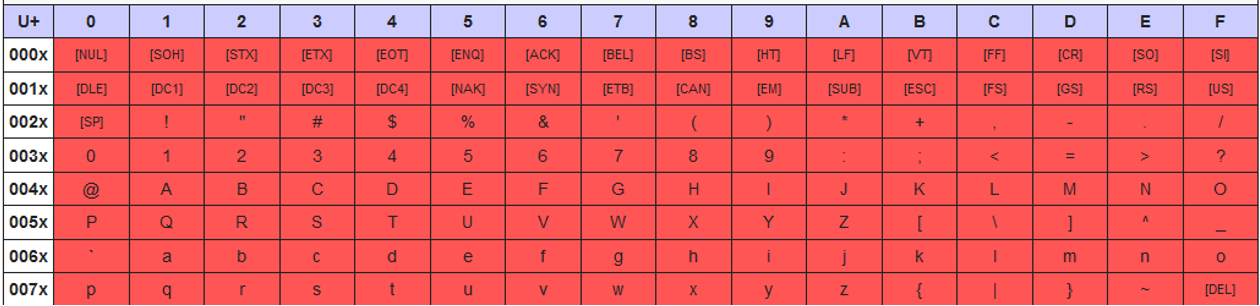
Die Latin-1-Zeichencodierung behandelt die Zeichen im Bereich von 0x80–0xFF wie im Unicodeblock Lateinisch-1, Ergänzung definiert.
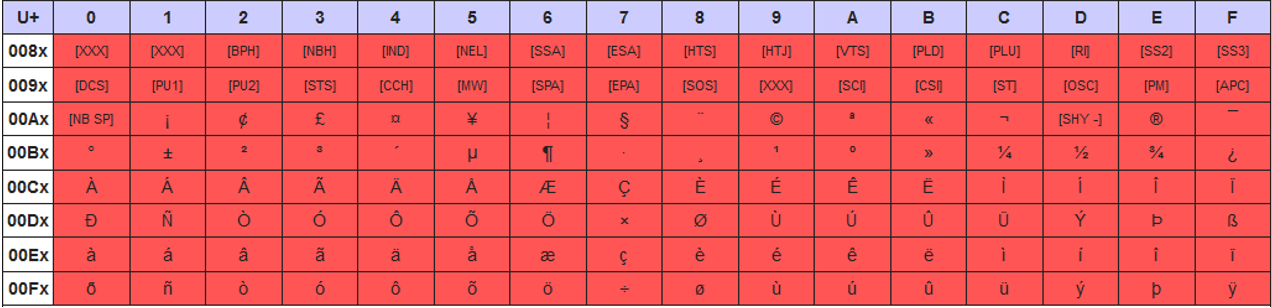
Die UTF-8-Zeichencodierung behandelt die Unicode-Zeichen von 0x80 als:
UTF-8-Bytefolge (binäre Darstellung)
Unicode-Bereich
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
UTF-8-Zeichencodierung verwenden
Schutzmaßnahmen
Die korrekte Handhabung der UTF-8-Zeichencodierung durch die Firmware-Befehle kann nicht garantiert werden und muss explizit und ausführlich überprüft werden.
Anmerkungen
Bei der Verwendung von UTF-8-Zeichenfolgen wird empfohlen, nur UTF-8-Zeichenfolgen zu verwenden und UTF-8- und Nicht-UTF-8-Zeichenfolgen nicht zu kombinieren.
Werden UTF-8- und Nicht-UTF-8-Zeichenfolgen kombiniert, sollten die Nicht-UTF-8-Zeichenfolgen nur Zeichen im Bereich 0x00–0x7F enthalten.
Funktionen wie LEN, MID, LEFT; INSERT, DELETE, RIGHT sind Byte-orientiert. Wenn sie mit UTF-8-Zeichenfolgen verwendet werden, stimmen die Bytezahlen und -positionen, die von der Funktion übernommen werden, möglicherweise nicht mit den Zeichenzahlen und -positionen der UTF-8-Zeichenfolge überein.
Beispiel
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operation
LEN(utf8#'敬具')Ergebnis
6
Wenn Byte-orientierte Zeichenfolgen-Funktionen mit UTF-8-Zeichenfolgen verwendet werden, deren Bytezahlen und -positionen nicht mit der Bytegröße und der Startbyteposition der UTF-8-Zeichen übereinstimmen, ist das Ergebnis eine ungültige UTF-8-Zeichenfolge.
Beispiel
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operation
MID(IN := utf8#'敬具', L := 3, P := 4)Ergebnis
utf8#'具' (' E5 85 B7')
Operation
MID(IN := utf8#'敬具', L := 3, P := 3)Ergebnis
'Œ$85' (' AC E5 85')
Wenn UTF-8-Ergebniszeichenfolgen größer sind als die Zielzeichenfolgen, kann das Ergebnis eine ungültige UTF-8-Zeichenfolge sein.
Beispiel
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
sString5 definiert als STRING[5]
Operation
sString5:=utf8#'敬具'Ergebnis
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
Sonderzeichen im Unicode-Bereich 0x80–0xFF führen zu unterschiedlichen Ergebnissen, je nachdem, ob sie als 8-Bit-Zeichenfolgen oder als UTF-8-Zeichenfolgen eingegeben werden.
Beispiel
Input
'ö' (' F6')
utf8#'ö' (' C3 B6')
Operation
LEN('ö')Ergebnis
1
Operation
LEN(utf8#'ö')Ergebnis
2
Operation
'ö'= utf8#'ö'
Ergebnis
FALSE
Die Suche nach einer 8-Bit-Zeichenfolge mit Zeichen im Bereich 0x80–0xFF in einer UTF-8-Zeichenfolge und umgekehrt kann zu unerwarteten Ergebnissen führen.
Beispiel
Input
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
Operation
FIND(IN1 := utf8#'敬具', IN2 :='å')Ergebnis
4
Zeichenkettenfunktionen mit EN/ENO
Kontaktplan (KOP) und Funktionsbausteinsprache (FBS)
In KOP und in FBS können STRING-Befehle mit Enable-Eingängen (EN) und Enable-Ausgängen (ENO) nicht aneinander gehängt werden. Hängen Sie zuerst die STRING-Befehle ohne EN/ENO aneinander an und fügen Sie abschließend einen Befehl mit EN/ENO hinzu. Der Enable-Eingang (EN) steuert dann die Ausgabe des Gesamtergebnisses.
Diese Anordnung ist nicht möglich:
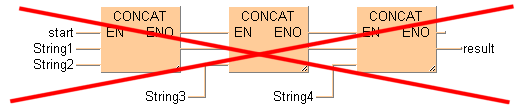
Diese Anordnung ist möglich:
