STRING
El tipo de datos STRING consta de dos partes:
Una cabecera que contiene el número de bytes máximo y actual
Una serie (una cadena) de hasta 32767 bytes, dependiendo del tamaño de la memoria del PLC, que puede contener cualquier tipo de codificación de caracteres e incluso datos binarios.
Para más información, consultar "Estructura de la memoria interna de las cadenas de caracteres en el PLC".
Ejemplos de operaciones con variables de tipo STRING:
Llenar variables de cadena mediante literales de cadena o mediante funciones de conversión como WORD_TO_STRING, FP_FORMAT_STRING...
Usar y manipular variables de cadena con instrucciones de cadena como CONCAT, LEFT...
Acceder arbitrariamente a variables de cadena mediante funciones de direccionamiento especiales como Adr_OfVarOffs… o mediante DUTs de solapamiento especiales como la DUT de solapamiento predefinida STRING32_OVERLAPPING_DUT
Intercambiar datos con dispositivos externos mediante archivos, páginas HTML o comandos de monitorización.
En Control FPWIN Pro7, las dos codificaciones de caracteres siguientes son especialmente compatibles con los literales de cadena y con la monitorización:
Codificación Latin-1, que es una codificación de caracteres fija de un byte según ISO 8859-1 (Latin-1) y que permite caracteres Unicode de 0x00 a 0xFF
Codificación UTF-8, que es una codificación de caracteres multibyte con caracteres que constan de 1 a 4 bytes, lo que permite todos los caracteres Unicode de 0x00 a 0x10FFFF
Las codificaciones de caracteres Latin-1 y UTF-8 tratan los caracteres del rango 0x00–0x7F de forma idéntica a los caracteres ASCII.
Se debe evitar mezclar las codificaciones de caracteres. Para más información, consultar "Cómo utilizar la codificación de caracteres UTF-8".
Literales
Los literales contienen una secuencia de caracteres dentro de comillas simples (').
Los literales se pueden usar del siguiente modo:
En los editores de declaración para inicializar una variable de tipo STRING
En los cuerpos de programación como argumentos de entrada
Están disponibles los siguientes literales de cadena:
Literales de cadena con codificación Latin-1 que permiten caracteres Unicode de 0x00 a 0xFF
Literales de cadena sin tipo con codificación Latin-1 sin ningún prefijo como 'abc'. Generan una advertencia cuando contienen caracteres no ASCII en el rango de 0x80 a 0xFF como 'äöü'.
Ejemplos de literales de cadena Latin-1 sin tipo:
Bloque Unicode
Literal de cadena Latin-1 sin tipo
Bytes en representación hexadecimal
Comentario
Carácter vacío
''
''
Basic Latin (0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
Este uso genera un mensaje de advertencia.
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
Literales de cadena tipados con codificación Latin-1 y prefijo latin1# como latin1#'abc' o latin1#'äöü'
Ejemplos de literales de cadena tipados en Latin-1:
Bloque Unicode
Literal de cadena tipado en Latin-1
Bytes en representación hexadecimal
Comentario
Carácter vacío
latin1#''
''
Basic Latin (0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Latin-1 Supplement (0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
Este uso no genera un mensaje de advertencia.
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
Literales de cadena UTF-8
Los literales de cadena UTF-8 con el prefijo utf8# como utf8#'abc', utf8#'äöü' o utf8#'ä+漢+🙏' pueden codificar todos los caracteres Unicode de 0x00 a 0x10FFFF e 1 a 4 bytes.
Ejemplos de literales de cadena UTF-8
Bytes por carácter
Bloque Unicode
Literal UTF-8
Byte en representación hexadecimal
Carácter vacío
utf8#''
''
1
Basic Latin
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
Latin-1 Supplement
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
Griego
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK Hirakana
utf8#'ゖ'
' E3 82 96'
CJK Katakana
utf8#'ヺ'
' E3 83 BA'
CJK Unified
utf8#'囆'
' E5 9B 86'
4
CJK Unified
utf8#'𫜴'
' F0 AB 9C B4'
Emoticono
utf8#'🙏'
' F0 9F 99 8F'
Secuencias carácter-espacio
Las secuencias carácter-espacio se pueden utilizar en los literales de cadenas de caracteres de 8 bits y en los literales UTF-8.
La combinación de hasta 3 grupos de caracteres: el signo dólar ($) seguido de dos dígitos hexadecimales; se interpretan como la representación hexadecimal de un carácter de 8 bits.
Literales
Bytes en representación hexadecimal
Comentario
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
NOTASi se introduce una secuencia de byte UTF-8 no válida en una cadena de caracteres UTF-8, el resultado será una cadena UTF-8 no válida.
Ejemplo
Entrada
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
sString10 definido como STRING[10]
Operación
sString10:= utf8#'敬敬$FE$FF敬具'Resultado
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
Las combinaciones de dos caracteres comenzando con el signo dólar, se interpreta como se muestra en la siguiente tabla:
Literales
Bytes en representación hexadecimal
Comentario
'$$'
utf8#'$$'
' 24'
Signo dólar
'$''
utf8#'$''
' 27'
Comilla simple
'$L' o '$l'
utf8#'$L' o utf8#'$l'
' 0A'
Salto de línea
'$N' o '$n'
utf8#'$N' o utf8#'$n'
' 0D 0A'
Nueva línea
'$P' o '$p'
utf8#'$P' o utf8#'$p'
' 0C'
Avance de Página
'$R' o '$r'
utf8#'$R' o utf8#'$r'
' 0D'
Retorno de carro
'$T' o '$t'
utf8#'$T' o utf8#'$t'
' 09'
Tabulación Horizontal
Monitorización dependiendo del tipo de cadena de caracteres
Durante la monitorización, seleccionar la representación por defecto para ver los bytes de la cadena de caracteres mostrados correctamente de acuerdo con la codificación de caracteres detectada:
Tipo de una cadena de caracteres |
Prefijos |
Representación por defecto |
Representación hexadecimal |
Ejemplo de programación en el editor ST |
|---|---|---|---|---|
Cadena con codificación Latin-1 |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (usar literal de cadena tipado en Latin-1 para evitar un mensaje de advertencia) |
|
Cadena de caracteres UTF-8 |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
Cadena de caracteres de tipo mixto |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
Monitorización en Introducir Datos a Monitorizar (EDM): Hay disponible dos representaciones: por defecto y hexadecimal.
Monitorización en los editores de programación: Representación por defecto en el cuerpo y en la ayuda contextual, representación hexadecimal solamente en la ayuda contextual.
Declaración de caracteres
Para declarar variables del tipo STRING en la cabecera de la POU utilizar la siguiente sintaxis:
STRING[n], donde n = número de caracteres
El valor por defecto para la declaración de variables en la cabecera de la POU o en la lista de variables globales, es '', es decir, una cadena vacía.
Cadenas de caracteres no válidas
Criterio para los caracteres no válidos:
El número máximo de bytes reservados para la cadena de caracteres es negativo o superior a 32767
El número real de bytes de la cadena de caracteres es negativo o superior a 32767
El número real de bytes de la cadena de caracteres es negativo o superior al número máximo de bytes reservado para la cadena de caracteres
Estructura de la memoria interna de las cadenas de caracteres en el PLC
Cada carácter de la cadena se almacena en un byte. El área de memoria que ocupa un string consiste en una cabecera (dos palabras) y en una palabra por cada dos caracteres.
La primera palabra contiene el número de caracteres reservado para la cadena.
La segunda palabra contiene el número real de caracteres de la cadena.
Las palabras siguientes contienen dos bytes, uno para cada carácter de la cadena.
Para reservar un área de memoria determinada para una variable tipo STRING[n], especificar la longitud de la cadena utilizando la siguiente fórmula:
Tamaño de la memoria = 2 palabras (cabecera) + (n+1)/2 palabras (bytes)
La unidad mínima para gestionar la memoria es la palabra (16 bits). Por lo tanto, el número de las palabras siempre se redondea al número entero siguiente.
Offset |
Byte de Mayor Peso |
Byte de Menor Peso |
|---|---|---|
0 |
Número máximo de bytes reservados para la cadena de caracteres |
|
1 |
Número real de bytes de la cadena de caracteres |
|
2 |
Byte 2 |
Byte 1 |
3 |
Byte 4 |
Byte 3 |
4 |
Byte 6 |
Byte 5 |
... |
... |
... |
1+(n+1)/2 |
Byte n |
Byte n-1 |
Codificaciones de caracteres
Las codificaciones de caracteres Latin-1 y UTF-8 tratan los caracteres del rango 0x00 a 0x7F de forma idéntica a los caracteres ASCII tal y como se define en el bloque Unicode "C0 Controls and Basic Latin"
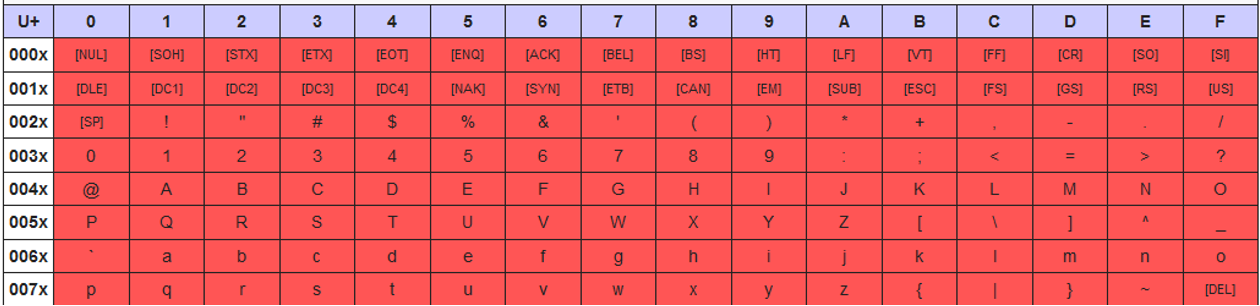
La codificación de caracteres Latin-1 trata los caracteres del rango 0x80 a 0xFF tal y como se define en el bloque Unicode «C1 controls and Latin-1 supplement».
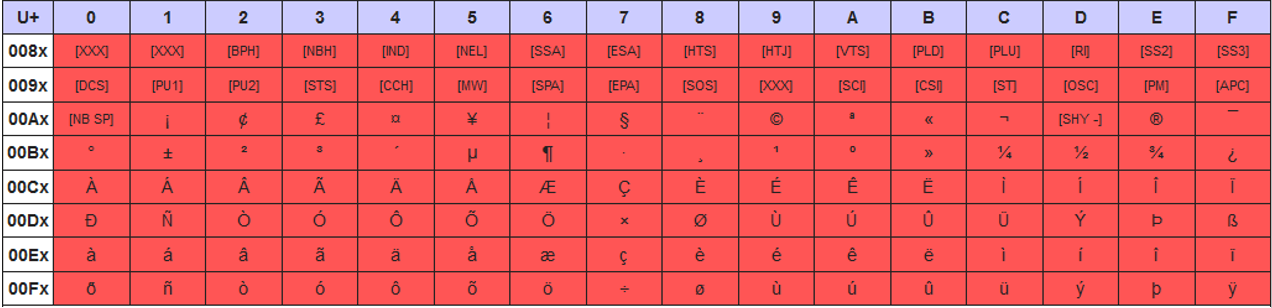
La codificación de caracteres UTF-8 trata los caracteres Unicode a partir de 0x80 como:
Secuencia de bytes UTF-8 (representación binaria)
Rango Unicode
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
Cómo utilizar la codificación de caracteres UTF-8
Precauciones
El manejo correcto de la codificación UTF-8 por instrucciones firmware no se puede garantizar y se debe chequear de modo explícito y en detalle.
Observaciones
¡Cuando se trabaja con caracteres UTF-8, es muy recomendable utilizar solamente caracteres UTF-8 y evitar mezclar codificaciones UTF-8 y non-UTF-8!
Si se mezclan cadenas de caracteres UTF-8 y no UTF-8, las cadenas no UTF-8 solo deben contener caracteres en el rango de 0x00 a 0x7F.
Funciones como LEN, MID, LEFT; INSERT, DELETE, RIGHT son de tipo byte. Cuando se utilizan con caracteres tipo UTF-8, es posible que el número de bytes y las posiciones que utiliza la función no se corresponden con los números y las posiciones de los caracteres UTF-8.
Ejemplo
Entrada
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operación
LEN(utf8#'敬具')Resultado
6
Cuando se utilizan funciones de caracteres orientadas a bytes con caracteres UTF-8 con número de bytes y posiciones que no se corresponden con el tamaño de los bytes y la posición inicial de los caracteres UTF-8, el resultado será un carácter UTF-8 no válido.
Ejemplo
Entrada
utf8#'敬具' (' E6 95 AC E5 85 B7')
Operación
MID(IN := utf8#'敬具', L := 3, P := 4)Resultado
utf8#'具' (' E5 85 B7')
Operación
MID(IN := utf8#'敬具', L := 3, P := 3)Resultado
'Œ$85' (' AC E5 85')
Si los caracteres UTF-8 resultantes tienen una longitud superior a la de los caracteres destino, se generará un carácter UTF-8 no válido.
Ejemplo
Entrada
utf8#'敬具' (' E6 95 AC E5 85 B7')
sString5 definido como STRING[5]
Operación
sString5:=utf8#'敬具'Resultado
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
Los caracteres especiales en el rango Unicode de 0x80 a 0xFF proporcionan resultados diferentes dependiendo de si se introducen como cadenas de caracteres de 8 bits o como caracteres UTF-8.
Ejemplo
Entrada
'ö' (' F6')
utf8#'ö' (' C3 B6')
Operación
LEN('ö')Resultado
1
Operación
LEN(utf8#'ö')Resultado
2
Operación
'ö'= utf8#'ö'
Resultado
FALSE
La búsqueda de una cadena de caracteres de 8 bits en el rango de 0x80 a 0xFF en la codificación UTF-8 y viceversa puede proporcionar resultados diferentes a los esperados.
Ejemplo
Entrada
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
Operación
FIND(IN1 := utf8#'敬具', IN2 :='å')Resultado
4
Funciones STRING con EN/ENO
Diagrama de contactos (LD) y diagrama de bloques de funciones (FBD)
Las instrucciones STRING con contactos EN/ENO, no se pueden conectar unas a otras en LD ni en FBD. Primero conectar las instrucciones STRING sin EN/ENO y después insertar una instrucción EN/ENO en la posición final. La entrada (EN) controla la salida del resultado global.
Esta disposición no es válida:
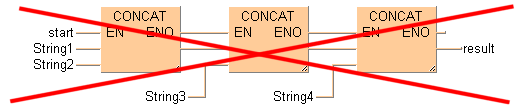
Esta disposición sí es válida:
