STRING
Le type de données STRING comprend deux parties :
Un en-tête qui contient le nombre maximum et le nombre actuel d’octets.
Une série (une chaîne de caractères) de jusqu’à 32767 octets selon la taille de la mémoire de l’automate, qui peut contenir tout type de codage de caractères et même des données binaires.
Pour en savoir plus, voir "Structure de la mémoire interne des chaînes de caractères sur l’automate".
Exemples avec des variables du type de données STRING :
Remplissage de variables chaines de caractères avec des littéraux chaînes de caractères ou des fonctions de conversion telles que WORD_TO_STRING, FP_FORMAT_STRING...
Utilisation et manipulation de variables chaînes de caractères avec des instructions chaînes de caractères telles que CONCAT, LEFT...
Accès arbitraire à des variables chaînes de caractères via des fonctions adresses spéciales telles que Adr_OfVarOffs… ou via des DUT avec éléments superposés spéciaux tels que le DUT avec éléments superposés prédéfini STRING32_OVERLAPPING_DUT
Échange de données avec des dispositifs externes via des fichiers, des pages HTML ou des commandes de monitoring
Dans Control FPWIN Pro7, les deux codages de caractères suivants sont compatibles avec les littéraux chaînes de caractères et le monitoring :
Le codage Latin-1, qui est un codage de caractères à 1 bit fixe conforme à ISO 8859-1 (Latin-1) permettant d’utiliser les caractères Unicode dans l’intervalle 0x00–0xFF
Le codage UTF-8, qui est un codage de caractères multi-octets avec des caractères compris entre 1 et 4 octets, et permettant d’utiliser tous les caractères Unicode dans l’intervalle 0x00–0x10FFFF
Les codages de caractères Latin-1 et UTF-8 traitent les caractères dans l’intervalle 0x00–0x7F de manière identique aux caractères ASCII.
Évitez de mélanger les codages de caractères. Pour en savoir plus voir "Comment utiliser le codage de caractères UTF-8"
Littéraux chaînes de caractères
Les littéraux chaînes de caractères se composent d’une suite de caractères ou de séquences d’échappement entre guillemets simples (').
Les littéraux chaînes de caractères peuvent être utilisés :
Dans les éditeurs de déclaration pour initialiser une variable de type de données STRING
Dans les corps d’un programme comme arguments d’entrée
Les littéraux chaînes de caractères suivants sont disponibles :
Les littéraux chaînes de caractères codés Latin-1 permettant des caractères Unicode dans l’intervalle 0x00–0xFF
Littéraux chaînes de caractères codé Latin-1 non typés sans préfixe par ex. 'abc'. Ils génèrent un avertissement lorsqu’ils contiennent des caractères non ASCII dans l’intervalle 0x80–0xFF tels que 'äöü'.
Exemples de littéraux chaînes de caractères Latin-1 non typés :
Bloc Unicode
Littéral chaîne de caractères Latin-1 non typé
Octets en représentation hexadécimale
Remarque
Chaîne de caractères vide
''
''
Latin de base (0x00–0x7F)
'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
'0-9'
' 30 2D 39'
'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Supplément Latin-1 (0x80–0xFF)
'¥£©®'
' A5 A3 A9 AE'
Un message d’avertissement est généré.
'歨'
' B5 A1 BF'
'äöüß'
' E4 F6 FC DF'
'ÄÖÜ'
' C4 D6 DC'
Littéraux chaînes de caractères codés Latin-1 typés avec le préfixe latin1# par ex. latin1#'abc' ou latin1#'äöü'.
Exemples de littéraux chaînes de caractères Latin-1 typés :
Bloc Unicode
Littéral chaîne de caractères Latin-1 typé
Octets en représentation hexadécimale
Remarque
Chaîne de caractères vide
latin1#''
''
Latin de base (0x00–0x7F)
latin1#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
latin1#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
latin1#'0-9'
' 30 2D 39'
latin1#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
Supplément Latin-1 (0x80–0xFF)
latin1#'¥£©®'
' A5 A3 A9 AE'
Aucun message d’avertissement n’est généré.
latin1#'歨'
' B5 A1 BF'
latin1#'äöüß'
' E4 F6 FC DF'
latin1#'ÄÖÜ'
' C4 D6 DC'
Littéraux chaînes de caractères en UTF-8
Les littéraux chaînes de caractères codés UTF-8 avec le préfixe utf8# par ex. utf8#'abc', utf8#'äöü' ou utf8#'ä+漢+🙏' peuvent coder tous les caractères Unicode dans l’intervalle 0x00–0x10FFFF en 1 à 4 octets.
Exemples de littéraux chaînes de caractères UTF-8 :
Octets par caractère
Bloc Unicode
Littéral chaîne de caractères en UTF-8
Octets en représentation hexadécimale
Chaîne de caractères vide
utf8#''
''
1
Latin de base
utf8#'!"#+-*/<>='
' 21 22 23 2B 2D 2A 2F 3C 3E 3D'
utf8#'?@/{}[]~'
' 3F 40 2F 7B 7D 5B 5D 7E'
utf8#'0-9'
' 30 2D 39'
utf8#'A-Z,a-z'
' 41 2D 5A 2C 61 2D 7A'
2
Supplément latin 1
utf8#'¥£©®'
' C2 A5 C2 A3 C2 A9 C2 AE'
utf8#'歨'
' C2 B5 C2 A1 C2 BF'
utf8#'äöüß'
' C3 A4 C3 B6 C3 BC C3 9F'
utf8#'ÄÖÜ'
' C3 84 C3 96 C3 9C'
Grec
utf8#'αβγ'
' CE B1 CE B2 CE B3'
3
CJK Hirakana
utf8#'ゖ'
' E3 82 96'
CJK Katakana
utf8#'ヺ'
' E3 83 BA'
CJK Unified
utf8#'囆'
' E5 9B 86'
4
CJK Unified
utf8#'𫜴'
' F0 AB 9C B4'
Emoticône
utf8#'🙏'
' F0 9F 99 8F'
Séquences d’échappement
Les séquences d’échappement peuvent être utilisées dans des littéraux chaînes de caractères 8 bits et des littéraux chaînes de caractères en UTF-8.
La combinaison de trois caractères, le signe dollar ($) suivi de deux chiffres hexadécimaux, doit être interprétée comme la représentation hexadécimale du code de caractères 8 bits.
Littéral chaîne de caractères
Octets en représentation hexadécimale
Remarque
'$02$03'
utf8#'$02$03'
' 02 03'
STX, ETX
'$E5$9B$86'
utf8#'$E5$9B$86'
' E5 9B 86'
utf8#'囆'
'$F0$9F$99$8F'
utf8#'$F0$9F$99$8F'
' F0 9F 99 8F'
utf8#'🙏'
NOTASi une séquence d’octets UTF-8 entrée dans une chaîne de caractères en UTF-8 est invalide, le résultat sera une chaîne de caractères en UTF-8 invalide.
Exemple
Entrée
utf8#'敬 敬$FE$FF敬 具' (' E6 95 AC FE FF E5 85 B7')
sString10 défini en tant que STRING[10]
Opération
sString10:= utf8#'敬敬$FE$FF敬具'Résultat
sString10: utf8?'敬敬þÿ敬具' (' E6 95 AC FE FF E5 85 B7')
La combinaison de deux caractères commençant par le signe dollar doit être interprétée de la façon suivante :
Littéral chaîne de caractères
Octets en représentation hexadécimale
Remarque
'$$'
utf8#'$$'
' 24'
Signe dollar
'$''
utf8#'$''
' 27'
Guillemet simple
'$L' ou '$l'
utf8#'$L' ou utf8#'$l'
' 0A'
Interligne
'$N' ou '$n'
utf8#'$N' ou utf8#'$n'
' 0D 0A'
nouvelle ligne
'$P' ou '$p'
utf8#'$P' ou utf8#'$p'
' 0C'
Page suivante
'$R' ou '$r'
utf8#'$R' ou utf8#'$r'
' 0D'
Retour chariot
'$T' ou '$t'
utf8#'$T' ou utf8#'$t'
' 09'
Tabulateur
Monitoring selon le type de chaîne de caractères
Pendant le monitoring, sélectionnez la représentation par défaut pour voir les octets chaînes de caractères affichés correctement selon le codage de caractères détecté :
Type de chaîne de caractères |
Préfixe |
Représentation par défaut |
Représentation hexadécimale |
Exemple de programmation avec l’éditeur ST |
|---|---|---|---|---|
Chaîne de caractères codée Latin-1 |
- |
'a+b+c' |
' 61 2B 62 2B 63' |
CONCAT('a','+','b','+','c') |
latin1# |
latin1#'ä+¥+©' |
' E4 2B A5 2B A9' |
CONCAT('ä','+','¥','+','©') (utiliser un littéral chaîne de caractères Latin-1 pour éviter un message d’avertissement) |
|
Chaîne de caractères en UTF-8 |
utf8# |
utf8#'ä+漢+🙏' |
' C3 A4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT (utf8#'ä','+',utf8#'漢','+',utf8#'🙏') |
Chaîne de caractères de type mixte |
latin1utf8? |
latin1utf8?'ä+漢+🙏' |
' E4 2B E6 BC A2 2B F0 9F 99 8F' |
CONCAT ('ä','+',utf8#'漢','+',utf8#'🙏') |
Monitoring dans Saisie des données du monitoring (EDM) : Deux représentations sont disponibles : par défaut et hexadécimale.
Monitoring dans les éditeurs de programmation : Représentation par défaut dans le corps et dans l’info-bulle, représentation hexadécimale uniquement dans l’info-bulle.
Déclaration de chaînes de caractères
Pour déclarer des variables de type STRING dans l’en-tête du POU, utilisez la syntaxe suivante :
STRING[n], n = nombre d’octets
La valeur initiale par défaut, par ex. pour les déclarations de variables dans l’en-tête du POU ou la liste des variables globales, est ", c.-à-d. une chaîne de caractères vide.
Chaînes de caractères invalides
Critères d’invalidité d’une chaîne de caractères :
Le nombre d’octets maximum, réservé pour les caractères de la chaîne de caractères, est négatif ou supérieur à 32767.
Le nombre d’octets actuel, contenu dans les caractères de la chaîne de caractères, est négatif ou supérieur à 32767.
Le nombre d’octets actuel, contenu dans les caractères de la chaîne de caractères, est supérieur au nombre d’octets maximum réservé pour la chaîne de caractères.
Structure de la mémoire interne des chaînes de caractères sur l’automate
Chaque caractère de la chaîne est sauvegardé dans un octet. La zone mémoire de la chaîne de caractères se compose d’un en-tête (deux mots) et d’un mot pour deux caractères.
Le premier mot contient le nombre d’octets, réservé pour la chaîne de caractères.
Le second mot contient le nombre actuel d’octets dans la chaîne de caractères.
Les mots suivants contiennent chacun deux octets des caractères de la chaîne de caractères.
Pour réserver une certaine zone mémoire pour STRING[n], indiquez la longueur de la chaîne de caractères à l’aide de la formule suivante :
Taille de la mémoire = 2 mots (en-tête) + (n+1)/2 mots (octets).
La mémoire est organisée en mots. Par conséquent, les nombres de mots sont toujours arrondis au nombre supérieur suivant.
Offset de mots |
Octet de poids fort |
Octet de poids faible |
|---|---|---|
0 |
Nombre d’octets maximum réservé pour les caractères de la chaîne de caractères |
|
1 |
Nombre d’octets actuel contenu dans les caractères de la chaîne de caractères |
|
2 |
Octet 2 |
Octet 1 |
3 |
Octet 4 |
Octet 3 |
4 |
Octet 6 |
Octet 5 |
... |
... |
... |
1+(n+1)/2 |
Octet n |
Octet n-1 |
Codages de caractères
Les codages de caractères Latin-1 et UTF-8 traitent les caractères dans l’intervalle 0x00–0x7F de manière identique aux caractères ASCII tels qu’ils sont définis dans le bloc Unicode Commandes C0 et Latin de base.
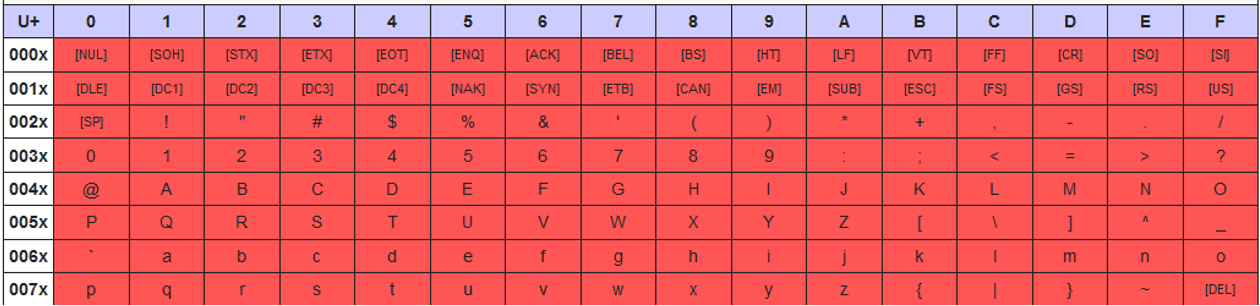
Le codage de caractères Latin-1 traite les caractères dans l’intervalle 0x80–0xFF, tels qu’ils sont définis dans le bloc Unicode Commandes C1 et Supplément Latin-1.
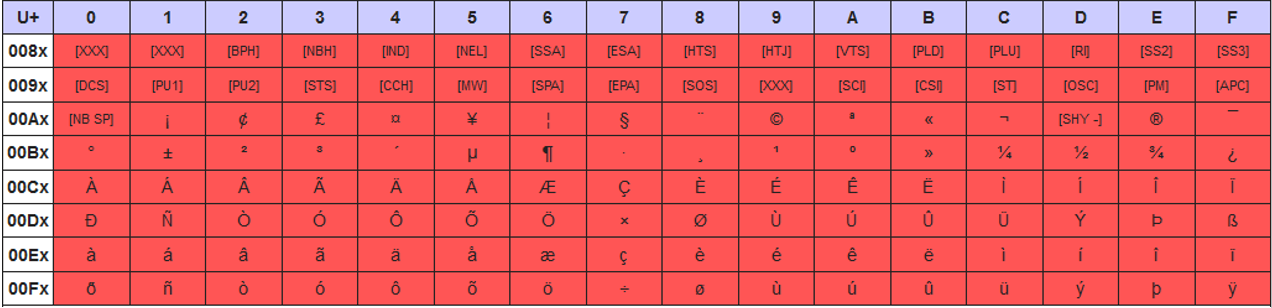
Le codage de caractères UTF-8 traite les caractères à partir de 0x80 ainsi :
Séquence d’octets UTF-8 (représentation binaire)
Intervalle Unicode
0xxxxxxx
0000 0000 – 0000 007F
110xxxxx 10xxxxxx
0000 0080 – 0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
0000 0800 – 0000 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0001 0000 – 0010 FFFF
Comment utiliser le codage de caractères UTF-8
Précautions
Un traitement correct du codage des caractères UTF-8 par les instructions du firmware n’est pas garanti. Une vérification détaillée est requise !
Remarques
Lorsque vous utilisez des chaînes de caractères en UTF-8, il est fortement recommandé d’utiliser exclusivement des chaînes de caractères en UTF-8 et d’éviter de mélanger des chaînes de caractères en UTF-8 et des chaînes de caractères non-UTF-8 !
Si vous mélangez des chaînes de caractères en UTF-8 et des chaînes de caractères non-UTF-8, les chaînes de caractères non-UTF-8 doivent uniquement contenir des caractères dans l’intervalle 0x00–0x7F.
Les fonctions telles que LEN, MID, LEFT; INSERT, DELETE, RIGHT sont orientées octets. Lorsqu’elles sont utilisées avec des chaînes de caractères en UTF-8, il est possible que les nombres et les positions des octets pris en compte par la fonction ne correspondent pas aux nombres et aux positions des caractères de la chaîne de caractères en UTF-8.
Exemple
Entrée
utf8#'敬具' (' E6 95 AC E5 85 B7')
Opération
LEN(utf8#'敬具')Résultat
6
Lorsque des fonctions chaînes de caractères orientées octets sont appliquées à des chaînes de caractères en UTF-8 avec des nombres et positions d’octets qui ne correspondent pas à la taille et à la position de l’octet de départ des caractères UTF-8, le résultat sera une chaîne de caractères en UTF-8 invalide.
Exemple
Entrée
utf8#'敬具' (' E6 95 AC E5 85 B7')
Opération
MID(IN := utf8#'敬具', L := 3, P := 4)Résultat
utf8#'具' (' E5 85 B7')
Opération
MID(IN := utf8#'敬具', L := 3, P := 3)Résultat
'Œ$85' (' AC E5 85')
Si le résultat est une chaîne de caractères en UTF-8 de taille supérieure à la chaîne de caractères de destination, le résultat peut être une chaîne de caractères en UTF-8 invalide.
Exemple
Entrée
utf8#'敬具' (' E6 95 AC E5 85 B7')
sString5 défini en tant que STRING[5]
Opération
sString5:=utf8#'敬具'Résultat
sString5: utf8?'敬å$85' (' E6 95 AC E5 85')
Les caractères spéciaux dans l’intervalle Unicode 0x80–0xFF génèrent des résultats différents selon qu’ils sont entrés en tant que chaînes de caractères 8 bits ou en tant que chaînes de caractères en UTF-8.
Exemple
Entrée
'ö' (' F6')
utf8#'ö' (' C3 B6')
Opération
LEN('ö')Résultat
1
Opération
LEN(utf8#'ö')Résultat
2
Opération
'ö'= utf8#'ö'
Résultat
FALSE
Rechercher une chaîne de caractères 8 bits avec des caractères dans l’intervalle 0x80–0xFF dans une chaîne de caractères en UTF-8 et vice versa peut aboutir à des résultats inattendus.
Exemple
Entrée
utf8#'敬具' (' E6 95 AC E5 85 B7')
'å' (' E5')
Opération
FIND(IN1 := utf8#'敬具', IN2 :='å')Résultat
4
Fonctions STRING avec EN/ENO
Schéma à contacts (LD) et diagramme de blocs fonctions (FBD)
Les instructions STRING avec contacts entrées et sorties de validation EN/ENO ne peuvent pas être connectées les unes aux autres en LD et FBD. Connectez d’abord des instructions sans EN/ENO puis ajoutez une instruction avec EN/ENO en dernière position. L’entrée de validation (EN) contrôle la sortie du résultat général.
Cette disposition n’est pas possible :
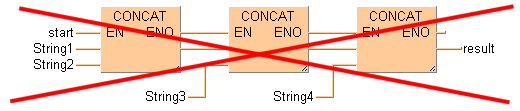
Cette disposition est possible :
